今天比较简单,不管我们创建一个PyStringObject是通过PyString_FromString还是通过PyString_FromStringAndSize,如果字符串实际上只是一个字符,则会进行如下操作:
[code lang=”C”]
PyObject *
PyString_FromStringAndSize(const char *str, Py_ssize_t size)
{
register PyStringObject *op;
if (size < 0) {
PyErr_SetString(PyExc_SystemError,
"Negative size passed to PyString_FromStringAndSize");
return NULL;
}
if (size == 0 && (op = nullstring) != NULL) {
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
if (size == 1 && str != NULL &&
(op = characters[*str & UCHAR_MAX]) != NULL)
{
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
if (size > PY_SSIZE_T_MAX – PyStringObject_SIZE) {
PyErr_SetString(PyExc_OverflowError, "string is too large");
return NULL;
}
/* Inline PyObject_NewVar */
op = (PyStringObject *)PyObject_MALLOC(PyStringObject_SIZE + size);
if (op == NULL)
return PyErr_NoMemory();
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
if (str != NULL)
Py_MEMCPY(op->ob_sval, str, size);
op->ob_sval[size] = ‘\0’;
/* share short strings */
if (size == 0) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
nullstring = op;
Py_INCREF(op);
} else if (size == 1 && str != NULL) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}
[/code]
先将所有的字符串字符对象进行intern机制处理,再将intern的结果缓存到字符缓冲池中,如下图所示:
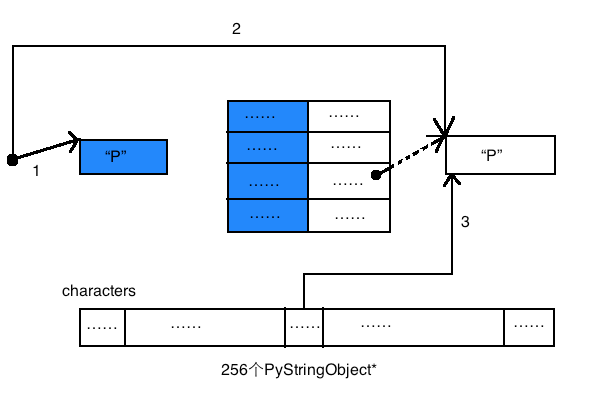
分为如下三步:
(1)、创建PyStringObject对象;
(2)、对对象进行intern操作;
(3)、将对象缓存到字符缓冲池中。
然后我们再看看python中和string相关的效率的问题,其实,python中我们都知道python的string字符串可以通过+号进行连接,这个看起来貌似要简单,但是简单就意味着效率的低下,如果我们用N个string进行拼接,则我们需要进行N-1次的内存访问和内存搬运,这非常严重的影响到了python的效率,所以我们通常使用join函数来进行字符串的拼接,join函数对存在list或tuple中的字符串进行连接操作这种做法只要分配一次内存,执行效率要高很多。
代码如下:
[code lang=”python”]
__author__ = ‘KarlDoenitz’
a = "".join(["hello", " ", "world", "!"])
print a
[/code]
好了,明天继续学习。
回家了? 🙂